
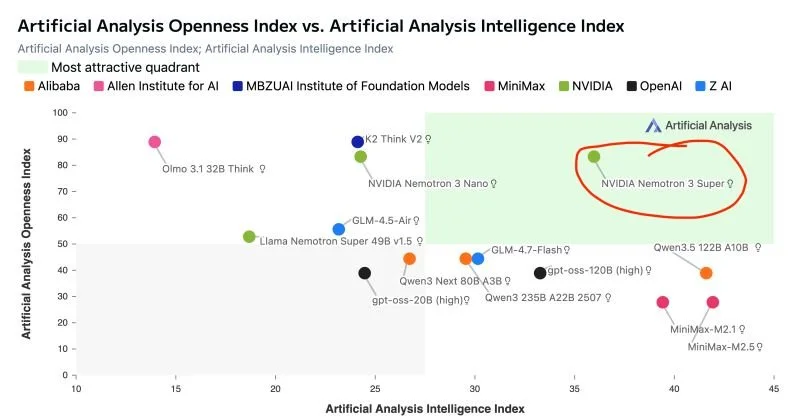
As I've highlighted in this chart, NVIDIA's new "Nemotron 3 Super" LLM stands alone in terms of openness and capability. It's also PERFECT for multi-agent workflows. Read on:
ARCHITECTURE
Nemotron 3 Super has 120 billion parameters, but only 12 billion are active at any time thanks to a Mixture-of-Experts (MoE) design. You get frontier-class knowledge at a fraction of the compute cost.
Combines transformer attention layers with Mamba state-space layers... a hybrid approach that delivers a practical one-million-token context window with efficient, linear-time sequence processing.
A novel LatentMoE technique compresses tokens before routing, allowing 4x as many expert specialists to be consulted per token versus a traditional MoE setup.
Multi-Token Prediction enables up to 3x speedup for structured generation tasks like code and tool calls.
PERFORMANCE
Up to 2.2x higher throughput than comparably-sized GPT-OSS-120B from OpenAI; up to 7.5x higher throughput than Qwen 3.5 (122B) from Alibaba Cloud... while matching or exceeding both on accuracy.
Pre-trained natively in 4-bit NVFP4 precision, pushing inference up to 4x faster on Blackwell GPUs versus FP8 on Hopper, with no accuracy loss.
Currently powers NVIDIA's AI-Q research agent to #1 on both DeepResearch Bench leaderboards.
WHY IT MATTERS FOR AGENTIC AI
Multi-agent workflows generate up to 15x more tokens than standard chat due to resending full histories, tool outputs and intermediate reasoning — the "context explosion" problem. A million-token context window lets agents retain full workflow state without truncation.
Complex agents need to reason at every step, but deploying large models for every subtask is too slow and costly. Nemotron 3 Super's sparse MoE + Mamba efficiency makes step-by-step reasoning affordable at scale.
OPENNESS & ADOPTION
NVIDIA is releasing open weights under a permissive commercial license, plus over 10 trillion tokens of training data, 15 RL training environments and full evaluation recipes.
Already being adopted by Perplexity (search) and CodeRabbit (coding assistant) as well as enterprises like Siemens and Palantir.
AVAILABILITY
Weights are on Hugging Face for self-hosting.
For cloud deployment, available via Google Cloud Vertex AI and Oracle Cloud.
For hassle-free inference, there are several options including Lightning AI (where I hold a fellowship), which offers amongst the fastest inference speeds: a whopping 480 output tokens per second (according to independent benchmarking by Artificial Analysis).
The SuperDataScience podcast is available on all major podcasting platforms, YouTube, and at SuperDataScience.com.