It is mighty hot in New York rn... but not nearly as spicy as the interviews on my podcast in June! ICYMI, here are the best bits of my on-air convos last month:
1. Two-time mega-bestselling O'Reilly author Chip Huyen on what's left for humans to do when the cost of building software is headed to $0.
2. Andrey Kurenkov, co-host of my favorite podcast ("Last Week in A.I.") and Founding A.I. Lead at Astrocade, on effective vibe-coding.
3. Lightning AI's VP of Infrastructure Frank Basso on what it's actually like inside an A.I. data center.
4. Gilbert Eijkelenboom on why 85% of data scientists can't communicate their work effectively... and the framework for fixing this.
5. In a role-reversal for landmark Episode #1001, the founder and original host of the SuperDataScience Podcast, Kirill Eremenko, interviewed me. In this clip, we discussed whether AGI would require something like consciousness to be realized.
The SuperDataScience podcast is available on all major podcasting platforms, YouTube, and at SuperDataScience.com.

Filtering by Category: Five-Minute Friday
Recursive Self-Improvement
Recursive Self-Improvement (RSI) is suddenly a term that's everywhere. What is RSI? How concerned should be about it? And how soon can we expect it? Here's the skinny:
WHAT IS RSI?
• The idea: An A.I. gets good enough at A.I. research to build a more capable successor, which builds an even better one, in a loop that compounds every turn.
• What we have today is *not* RSI but "A.I.-assisted coding", in which humans still set the goals and judge the results (actual RSI takes the human out of the loop, as shown in the diagram).
• RSI isn't a new concept; it's been around since at least 1965 when mathematician I.J. Good described an "intelligence explosion".
WHAT'S THE CONCERN?
RSI could unleash Artificial Superintelligence (ASI) and "the singularity", a point beyond which there could be radical abundance and radically positive outcomes for humanity... but we have no idea what will happen beyond the singularity and that's also a cause for concern (e.g., human extinction risk, Terminator-style "SkyNet", etc.).
HOW CLOSE ARE WE TO RSI?
• Anthropic reports that, as of May 2026, over 80% of code merged into its production codebase was written by Claude — up from low single digits before early 2025.
• On the hardest open-ended problems, its models' success rate jumped from under 20% in late 2025 to 76% by May.
• Think-tank METR finds the length of tasks A.I. can handle solo is now doubling roughly every four months, up from the "doubling every seven months" trend of the past few years.
• Anthropic co-founder Jack Clark puts a 60% chance on an A.I. creating its own successor, with no human involved, by the end of 2028.
REASONS TO BE SKEPTIC
• Skeptics flag two bottlenecks: compute (chips are scarce) and data (success is hard to verify outside code and math, risking "recursive drift").
• Others note the gap between today's coding agents and real RSI is wider than the hype suggests.
BOTTOM LINE
The productivity gains from coding assistants are real, accelerating rapidly and already in your hand. The closer we get to systems that improve themselves, the more it pays to keep human checkpoints, monitoring and oversight firmly in place.
Listen to the most recent episode of my podcast (Episode #1004) to hear more on all of the above, including what you can do personally to mitigate the risks of RSI if that's a way you might like to make an impact!
The SuperDataScience podcast is available on all major podcasting platforms, YouTube, and at SuperDataScience.com.
Fable 5: The Full Story from Capabilities to Drama
The dust has settled, allowing me to provide you with all the key context you need to know on Fable 5, the most capable A.I. model ever offered to the public, and the US government forcing it off shelves three days later:
A NEW CLASS OF MODEL
• Anthropic stacks its models in tiers: Haiku (small and fast), Sonnet (the capable middle) and Opus (the powerful top). Sitting above all of them now is a "Mythos-class" tier.
• Fable 5 and its locked-down sibling Mythos 5 are the same underlying model... the only difference is the safeguards.
• Mythos 5 goes to trusted cyberdefenders with guardrails largely lifted; Fable 5 went to the public with them switched on.
WHAT IT COULD DO
• State-of-the-art on nearly every benchmark Anthropic tested... and the lead grows the longer and more complex the task (see chart).
• Stripe ran a codebase-wide migration on 50M lines of Ruby in a single day; work estimated at 2+ months for a full engineering team.
• Beat video "Pokémon FireRed" from raw screenshots alone, and got a 3x bigger memory boost than Opus on "Slay the Spire".
• Priced at $10/$50 per million input/output tokens: roughly 2x Opus 4.8, but under half the original Mythos Preview.
SAFETY BY DESIGN
• Classifiers watch three sensitive areas: cybersecurity, biology/chemistry and distillation (extracting a model to train a rival).
• Flagged requests quietly fall back to Opus 4.8 and the user is told.
• Triggers fire in under 5% of sessions. Anthropic admits it tuned conservatively, so some harmless prompts get bounced too.
THE THREE-DAY SHUTDOWN
• On Friday evening the federal government ordered Anthropic to switch off both Fable 5 and Mythos 5 worldwide, citing national security.
• The mechanism was an export-control action covering foreign nationals everywhere (including even, say, Canadian Anthropic employees living in the US!)... so broad that Anthropic pulled the model for absolutely everyone.
• The trigger was a reported jailbreak of the cyber safeguards by Amazon. Anthropic disputes its severity, calling it narrow and non-universal.
BOTTOM LINE
A premium-tier model, wrapped in deliberately cautious safeguards, pulled by its own government not long before Anthropic's reported IPO and the latest in a public battle between the firm and the federal government. Sessions now fall back to Opus 4.8. Whether Fable returns (and on what terms) depends on a fight that's far from over.
The SuperDataScience podcast is available on all major podcasting platforms, YouTube, and at SuperDataScience.com.
Ten Years of the Super Data Science Podcast, with Jon, Kirill and Special Guests
Today, we published Episode #1000 of the SuperDataScience Podcast! To celebrate, the show's original host Kirill Eremenko joined me and dozens of regular listeners on air to predict what the next 10 years of A.I. will bring.
In a bit more detail:
• We publish 104 episodes per year so Episode #1000 coincides with the show being about ten years old.
• The show was founded by Kirill Eremenko in 2016, who hosted over 400 episodes before handing me the reins in 2021.
• In a first for the show, Episode #1000 was streamed live online with our audience invited to join on air.
• Most folks interacted via chat functionality but a number of surprise guests came right onto the recording including Natalie Ziajski and Mario Pombo from the podcast team, rockstar A.I. entrepreneur Jepson Taylor, my 96-year-old grandmother and my very own pa, William Krohn.
• Kirill and I looked back on a decade of the podcast and fielded listener questions on topics such as A.I.’s biggest opportunities, the build-versus-buy dilemma, how to break into the field today, and how to stay grounded amid the relentless pace of A.I.
Thank you for support and listenership over all these years — we make this show for you and couldn't do it without you! We're excited to see what the next decade brings :)
The SuperDataScience podcast is available on all major podcasting platforms, YouTube, and at SuperDataScience.com.
In Case You Missed It in May 2026
Well, I certainly learned a lot from the outstanding guests we had on my podcast in May. ICYMI, today's episode features the best parts of my conversations with them:
1. Rubrik's Anneka Gupta and Cal Al-Dhubaib on how, in the Mythos era, the old cybersecurity playbook of prevention and detection is no longer enough, and how A.I. agents themselves are becoming a new source of data exposure inside organizations.
2. marimo's Dr. Trevor Manz on why code notebooks have become the natural working memory for A.I. coding agents. Trevor walks me through the Marimo Pair skill, which lets you drive a notebook from your agent, collaborating with Claude Code or Codex in real time as you load, explore, and visualize your data.
3. Jazmia Henry of collide. walks me through her work as a "full-stack" foundation model builder. We cover all four stages of the process: the often unglamorous slog of data curation, building bespoke tokenizers and embeddings, model training and reinforcement learning, and the inference layer that serves it all to end users.
4. Jacob Miller and Jeremy Mumford of Pattern (and authors of the great, brand-new book "Architected Intelligence") argue that the most expensive AI mistake an organization can make is failing slowly and sticking with prototypes long past their sell-by date because the traditional software mindset says you have to. We, of course, also discuss a solution.
The SuperDataScience podcast is available on all major podcasting platforms, YouTube, and at SuperDataScience.com.
AI’s Putting Recent Grads Out of Work; Here’s How to Get Hired Anyway!
Computer science/engineering grads had an employment advantage (see chart) that, since ChatGPT's release, has disappeared. Is A.I. to blame? Here's what the data say and what new grads (or anyone!) can do about it:
THE EMPLOYMENT LANDSCAPE
• NY Fed: unemployment for recent computer-science grads (22-27) sits at 7.0%, and computer engineering at 7.8% (roughly on par with fine arts and anthropology grads!)
• Compare that to ~5.8% for recent grads overall and ~4% for the whole US workforce.
• Eighteen-year-olds are voting with their feet: US undergrad CS enrolment fell 11% in 2025; computer programming fell a stunning 26%.
• Demand is shrinking too: Handshake postings are down ~50% from their 2022 peak, and Revelio Labs data suggest entry-level software and data-analysis postings have dropped as much as 67%.
IS A.I. TO BLAME?
• "Yes" camp: A 2025 Stanford University study found employment for 22-25-year-olds in A.I.-exposed jobs dropped 13% since 2022, while older workers held steady. The Dallas Fed replicated it... and the decline comes from juniors never being hired, not layoffs.
• "Not so fast" camp: Google economists found posting declines were just as steep for senior workers and predate ChatGPT. A Fed study of 1M+ firms found "null effects." Their take: high interest rates and a post-pandemic hangover, with A.I. as a convenient scapegoat.
WHAT YOU CAN DO:
1. Stop competing on raw code. The human edge is now system design, architecture and deciding what to build in the first place.
2. Pick a domain. "A.I. engineer" is a common résumé; "A.I. engineer who worked alongside a hospital team for two summer internships" is a short list.
3. Build a public portfolio. Substantive GitHub repos and a Kaggle project beat CVs sent into the void.
4. Get fluent with agentic tooling, e.g., RAG, model evaluation, multi-agent orchestration. PwC found A.I.-skilled workers earn a 56% wage premium (!!!)
5. Lean on your network. Referrals and warm intros are crushing mass (often GenAI-produced) applications in this market.
The SuperDataScience podcast is available on all major podcasting platforms, YouTube, and at SuperDataScience.com.
Tokenmaxxing vs AI Hardware Bottlenecks
Humans (like Reinforcement Learning algos) can "reward hack": "Tokenmaxxing" being a perfect example, after employers started using "number of tokens" consumed as a proxy for developers' productivity.
Even if humans weren't engaging in this pointless time-, money- and energy-consuming behavior, however, demand for A.I. compute is so vast that everyone's scrambling to to make more available. Alas, four tricky hardware bottlenecks face us:
1. GPUs:
• NVIDIA data-center GPU lead times now run 36–52 weeks, with Blackwell chips sold out through mid-2026.
• The real choke point isn't fabrication: It's TSMC's "CoWoS" advanced packaging, which is sold out through 2026. Nvidia alone has locked up ~60% of CoWoS capacity through 2027.
2. High-Bandwidth Memory (HBM):
• Demand has quintupled since 2023, and only three companies (SK hynix, Samsung and Micron) make it.
• All three are sold out well into 2026 and new HBM factories take 18–24 months to come online.
3. CPUs:
• As workloads shift toward agentic AI, the CPU:GPU ratio jumps from ~1:12 (for GenAI-only chatbots) to 1:1.
• Intel's CFO says the server-CPU shortfall "starts with a B" — billions in unmet demand so server CPU prices are up 10–20% in just the past couple of months.
4. Electricity: Hyperscaler build-outs are now gated by grid interconnect (18–36 months) and transformer lead times.
THE BIG MISMATCH
• The top 5 hyperscalers alone (Alphabet, Amazon, Meta, Microsoft and Oracle) are on track for ~$725B in combined 2026 capex.
• That's roughly 6x the hyperscalers' 2022 spend, with ~75% going to A.I. infrastructure.
• Hardware suppliers, however, have grown capex by only ~50%.... a 6x increase in demand met by only a 50% increase in supply is a big mismatch!
REASONS FOR OPTIMISM
Demand will continue to be high but I'm optimistic we'll continue to squeeze more juice from every lemon because, e.g.:
• Algorithmic efficiency keeps improving — Google's TurboQuant recently briefly tanked memory stocks by promising to materially cut inference memory needs.
• LLM efficiency gains via mixture-of-experts and smarter inference scheduling continue to compound.
• The tokenmaxxing trend is a corporate farce that will fade.
The SuperDataScience podcast is available on all major podcasting platforms, YouTube, and at SuperDataScience.com.
In Case You Missed It in April 2026
Whoa, it's May Day... and our podcast-production team was *on the ball* with getting our ICYMI-in-April episode together lickety-split. In case you missed it, these were the best bits of my on-air convos last month:
1. Oracle's Director of A.I. Developer Experience Richmond Alake defines the four types of memory A.I. agents can have... and the biological inspiration for each of them.
2. Matthew J. Glickman, co-founder/CEO of Genesis Computing, describes how A.I. agents allow data engineers to dramatically scale up their impact in an enterprise.
3. The A.I. infrastructure engineer Linda Haviv has amassed a following of over 250,000 folks on social media. In her clip from last month, she combines both worlds — detailing why A.I. infrastructure has now become everyone's problem while also discussing her work in lowering the barrier to access A.I. education.
4. Traci Walker Griffith, principal of The Eliot School in Boston, shares her novel perspective on what critical thinking is... in the context of how fifth-graders are leveraging A.I. to evaluate their work and prepare for tests.
The SuperDataScience podcast is available on all major podcasting platforms, YouTube, and at SuperDataScience.com.
Building Hardware is Hard but AI Agents Help, with Kishore Subramanian
In software, when something goes wrong, you push a patch. In hardware? Oooph. You're dealing with big headaches and huge costs. Thankfully, my guest today — Kishore Subramanian — is using AI to transform the way physical products get built for the better.
Kishore:
• Is CTO of Propel Software, a Bay Area company that combines product data with agentic AI to make the production of physical hardware (including high tech and medtech devices) as seamless as possible.
• Prior to Propel, held senior engineering roles at Google, where he worked on Google Assistant, so he has particularly rich experience with agent development.
• Holds a degree in electronics, computers and process control… as well as a 200-hour yoga-teaching certificate!
In this episode, Kishore covers:
• How product lifecycle management (PLM) is the system that takes a physical product from concept all the way to the customer and beyond.
• How AI agents can review engineering change orders — the hardware equivalent of pull requests — to flag risks, compliance gaps, and downstream impacts before they become expensive problems.
• How Propel built their AI platform, Propel One, on top of Salesforce's Agentforce 360 Platform, which gave them security, governance, data infrastructure, and a reasoning engine out of the box, allowing them to ship in about six months.
The SuperDataScience podcast is available on all major podcasting platforms, YouTube, and at SuperDataScience.com.
Building AI Agents Where 99.9% Accuracy Isn't Good Enough, with Raju Malhotra
The headlines shout “SaaSpocalypse,” but I don’t buy it. Neither does my guest today, Raju Malhotra, who argues that, thanks to humans collaborating with agents on optimized workflows, the SaaS opportunity is now far bigger than ever before.
More on Raju:
Chief Product & Technology Officer (CPTO) at Certinia, an Austin, Texas-based company whose Professional Services Automation software is used by over 1400 organizations around the world.
Was previously CPTO at PAR Technology and Khoros.
Earlier, spent 12 years at Microsoft working on cornerstone products like Visual Studio .NET.
Holds an MBA from The Wharton School and an undergrad in computer engineering.
In this episode, we cover:
Traditional SaaS isn't dead… instead, it's evolving into a hybrid of SaaS plus agentic capabilities, where humans and agents work together in optimized workflows.
By removing the human-skills constraint from professional services delivery, the agentic revolution could expand the addressable market by 7-8X.
The Agentforce 360 platform (by combining probabilistic AI with deterministic logic and guardrails) empowers innovators to turn their ideas into scalable software businesses, allowing businesses like Certinia to bring AI agents securely and reliably to their customers, even in sensitive industries where 0.1% error rates are unacceptable.
The SuperDataScience podcast is available on all major podcasting platforms, YouTube, and at SuperDataScience.com.
AI Making Theoretical Physics Breakthroughs
A.I. is now directly advancing science. "SuperChat", a powerful internal OpenAI model, recently helped crack a particle physics problem that had stumped researchers for over a year. Here's what happened:
THE PROBLEM
Four theoretical physicists (from Harvard, the Institute for Advanced Study, Cambridge and Vanderbilt) had been studying interactions involving gluons — the particles that "glue" quarks together inside protons and neutrons, essentially holding all matter together.
For decades, textbooks said a specific type of gluon interaction (called "single-minus" configurations) had a "scattering amplitude" of zero (i.e., these interactions simply could not occur).
The team suspected otherwise, and proved it for small numbers of gluons... but as they tried to generalize the formula, the expressions became dozens of terms long and unworkable. After about a year of grinding away by hand, they were stuck.
THE BREAKTHROUGH
They fed their complicated formulae into GPT-5.2 Pro. The model simplified an expression with 32 variables down to a compact product fitting on a single line.
Asked to generalize for any number of gluons, the model replied within minutes with what it called (I love this!) the "obvious" generalization.
A more powerful internal OpenAI model (which the researchers called "SuperChat") then produced a formal proof after about 12 hours of autonomous reasoning. The physicists checked step by step and confirmed it was correct.
The team then extended the approach to gravitons (hypothetical particles thought to carry the gravitational force), releasing the results in their second arXiv preprint a few weeks later.
CAVEATS
These are preprints, not yet peer-reviewed papers.
The results apply to a very specific mathematical regime at the simplest level of calculation ("tree level").
Human physicists were essential for defining the problem, providing the initial data and verifying the output.
WHY IT MATTERS
As one researcher put it: The hard part is no longer the physics itself; the hard part is now verifying the results and writing them up. AI compressed months of work into weeks.
This may be a template for AI-assisted research more broadly: AI generates conjectures from patterns in the data, human experts verify those conjectures through rigorous math and physical consistency checks.
It's not autonomous AI science; it's augmented human science. And that model could scale across disciplines, from pure math to drug discovery to materials science
The SuperDataScience podcast is available on all major podcasting platforms, YouTube, and at SuperDataScience.com.
A Post-Transformer Architecture Crushes Sudoku (Transformers Solve ~0%)
A game millions of people solve over morning coffee is exposing a fundamental weakness in the Transformer-based LLMs that dominate A.I. today. Here's why Sudoku matters for the future of A.I.:
THE BENCHMARK
Pathway tested its post-transformer architecture, BDH (Baby Dragon Hatchling 🐲) against "Sudoku Extreme," a collection of ~250,000 of the hardest Sudoku puzzles available.
Leading LLMs (such as o3-mini, DeepSeek-R1, Claude 3.7 Sonnet) scored effectively zero percent.
BDH, in stark contrast, solved them at 97.4% accuracy. That's not a marginal gap... it's a categorical one.
WHY SUDOKU IS A GREAT A.I. TEST
Sudoku is a constraint-satisfaction problem: Every move must satisfy multiple rules simultaneously across rows, columns and boxes. It demands search, tracking and backtracking — well beyond pattern-matching.
This makes it a clean proxy for real-world reasoning in medicine, law, operations, planning and tons of other fields, where you balance competing constraints under uncertainty.
WHY TRANSFORMERS STRUGGLE
LLMs turn every problem into text and solve it by predicting the next token. That works brilliantly for language tasks... but Sudoku doesn't live in language.
A transformer's internal state is constrained to ~1,000 floating-point values per token, and each decision gets locked in as text is generated. It can't hold multiple candidate strategies in parallel or backtrack without verbalizing every step.
WHAT BDH DOES DIFFERENTLY
BDH maintains a much larger internal "latent reasoning space" that isn't forced into text (think of a chess grandmaster playing 20 blindfold games without whispering moves to herself).
It uses sparse positive activations (~5% of neurons firing at any time), far more biologically plausible than the dense activation in transformers.
It's a state-based model (no standard attention mechanism), continuously updating internal state that's inspired by biological neuroscience (called Hebbian learning: "neurons that fire together wire together").
It achieves continual learning: BDH can pick up a new game's rules and reach advanced-beginner level in ~20 minutes, then improve through play... at roughly 10x lower cost than the Transformer-based LLMs achieve their near-zero scores.
CAVEAT
BDH is still early: It has been demonstrated at a ~1 billion parameter scale (comparable to GPT-2), not yet at frontier scale.
BOTTOM LINE
...but the data are clear: 0% vs. 97.4% is not incremental. It suggests the transformer's reasoning ceiling is real and alternative architectures can address it. Exciting to see alternatives to the dominant but limiting Transformer architecture emerge!
The SuperDataScience podcast is available on all major podcasting platforms, YouTube, and at SuperDataScience.com.
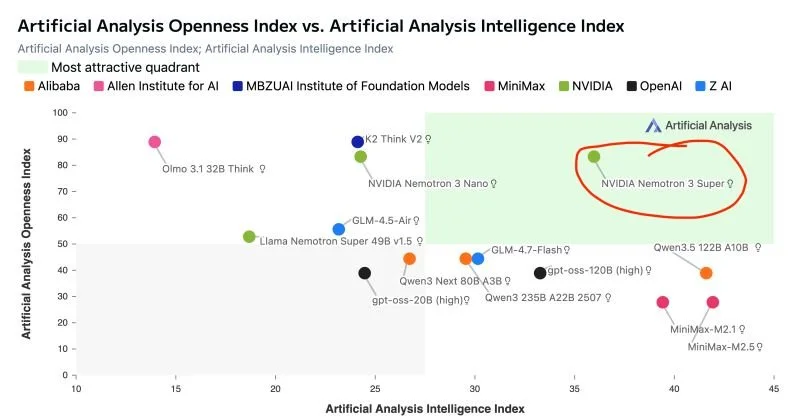
NVIDIA’s Nemotron 3 Super: The Perfect LLM for Multi-Agent Systems
As I've highlighted in this chart, NVIDIA's new "Nemotron 3 Super" LLM stands alone in terms of openness and capability. It's also PERFECT for multi-agent workflows. Read on:
ARCHITECTURE
Nemotron 3 Super has 120 billion parameters, but only 12 billion are active at any time thanks to a Mixture-of-Experts (MoE) design. You get frontier-class knowledge at a fraction of the compute cost.
Combines transformer attention layers with Mamba state-space layers... a hybrid approach that delivers a practical one-million-token context window with efficient, linear-time sequence processing.
A novel LatentMoE technique compresses tokens before routing, allowing 4x as many expert specialists to be consulted per token versus a traditional MoE setup.
Multi-Token Prediction enables up to 3x speedup for structured generation tasks like code and tool calls.
PERFORMANCE
Up to 2.2x higher throughput than comparably-sized GPT-OSS-120B from OpenAI; up to 7.5x higher throughput than Qwen 3.5 (122B) from Alibaba Cloud... while matching or exceeding both on accuracy.
Pre-trained natively in 4-bit NVFP4 precision, pushing inference up to 4x faster on Blackwell GPUs versus FP8 on Hopper, with no accuracy loss.
Currently powers NVIDIA's AI-Q research agent to #1 on both DeepResearch Bench leaderboards.
WHY IT MATTERS FOR AGENTIC AI
Multi-agent workflows generate up to 15x more tokens than standard chat due to resending full histories, tool outputs and intermediate reasoning — the "context explosion" problem. A million-token context window lets agents retain full workflow state without truncation.
Complex agents need to reason at every step, but deploying large models for every subtask is too slow and costly. Nemotron 3 Super's sparse MoE + Mamba efficiency makes step-by-step reasoning affordable at scale.
OPENNESS & ADOPTION
NVIDIA is releasing open weights under a permissive commercial license, plus over 10 trillion tokens of training data, 15 RL training environments and full evaluation recipes.
Already being adopted by Perplexity (search) and CodeRabbit (coding assistant) as well as enterprises like Siemens and Palantir.
AVAILABILITY
Weights are on Hugging Face for self-hosting.
For cloud deployment, available via Google Cloud Vertex AI and Oracle Cloud.
For hassle-free inference, there are several options including Lightning AI (where I hold a fellowship), which offers amongst the fastest inference speeds: a whopping 480 output tokens per second (according to independent benchmarking by Artificial Analysis).
The SuperDataScience podcast is available on all major podcasting platforms, YouTube, and at SuperDataScience.com.
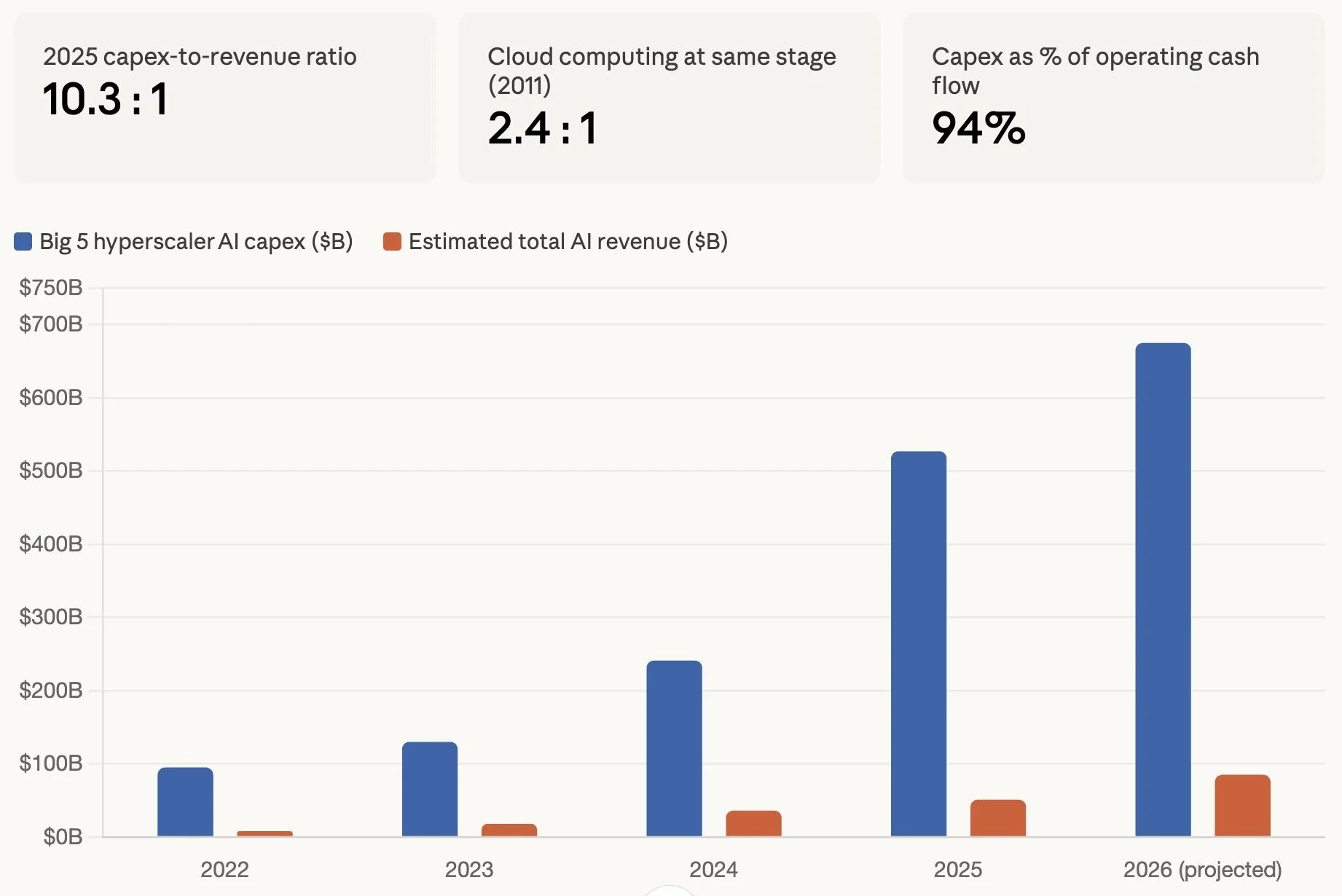
When Will The AI Bubble Burst? How Bad Will It Be?
There's mounting evidence that we're in an A.I.-infrastructure investment bubble... but, even if investors lose their shirts, an A.I. bubble bursting would be great news for most of us! How could this be? Read on:
A BUBBLE IS LIKELY HERE
The bull case is that this we're in a boom and the fundamentals will catch up, however various data suggest we're in a bubble.
E.g., OpenAI alone has committed to $600B–$1.4T in infrastructure spending over the coming years — staggering for a company generating ~$13B in annual revenue.
As shown in the chart I made for this post, the five largest hyperscalers had a 10:1 capex-to-revenue ratio in 2025, which dwarfs the 2:1 ratio for cloud-computing investment at the ~same stage.
With capex at 94% of operating cash flow, companies like Google that have famously large cash piles are now issuing bonds.
Circular financing is inflating numbers: NVIDIA pumped $100B into OpenAI so that OpenAI can build data centers full of NVIDIA chips.
WHY BUBBLES AREN'T ALL BAD
Investor Byrne Hobart, CFA argues in his book "Boom" that bubbles have powered many of humanity's greatest breakthroughs — from semiconductors to the Apollo program.
His key insight: participants in a tech race build economic complements to one another. Rising asset prices signal the tech is real, encouraging the investments that make the whole ecosystem work — a self-fulfilling prophecy, but a productive one.
HISTORICAL EVIDENCE
Dot-com era: telecom companies laid 80M+ miles of fiber-optic cable. Most went bankrupt... but bandwidth costs dropped 90%, giving us YouTube, Netflix and cloud computing.
Britain's 1840s railway mania ruined the original investors, yet the network became the backbone of the Industrial Revolution.
Therefore: bubbles leave behind infrastructure the rest of us benefit from for decades.
A WORD ON TIMING
Hobart notes that media called dot-com trading "nutty" back in 1995. Yet at the Nasdaq's post-crash low in 2002, it was still 40% above 1995 levels.
Warning signs of a bubble precede the peak by an unpredictable amount. Acting on them too early can leave you worse off.
WHAT CAN YOU DO?
Diversify your skill set: go deeper into fundamentals (model architecture, optimization, evaluation) rather than relying on wrappers around a single vendor's LLMs.
Build a financial cushion: bubbles create paper wealth and inflated comp packages. Don't let lifestyle inflation consume all of it.
Invest in your network and reputation: When hiring freezes thaw, the people who get picked up first are those other practitioners already know and respect.
The SuperDataScience podcast is available on all major podcasting platforms, YouTube, and at SuperDataScience.com.
The “100x Engineer”: How to Be One, But Should You?
This image shows a 3x3 grid of terminals, allowing 9 code-generating agents to be supervised. This is one of Peter Steinberger's tricks to being a "100x Engineer". What are his other tricks? Read on...
THE PHASE SHIFT
Andrej Karpathy (OpenAI co-founder, former Tesla AI director) recently went from 80% manual coding to 80% AI agent coding in just weeks; he says he's now "mostly programming in English."
This rapid phase shift was facilitated by tools like Anthropic's Claude Code, which (as many of us have experienced personally) have vastly improved their accuracy and capability in the past few months.
THE 100x ENGINEER
Developer Peter Steinberger racked up ~6,500 commits over two months adding 2.5 million lines of code (and removing 1.9 million). Many engineering teams ship a few hundred commits per month; he was doing an average of >200 per day!
His setup: 3–9 AI coding agents (e.g., Claude Code) running simultaneously in a grid of 3x3 terminal windows, rotating attention across them like a conductor directing an orchestra.
THE COUNTERINTUITIVE 100x WORKFLOW
Steinberger now spends *more* time planning, not less. His ratio has flipped from the traditional ~20% planning / 80% coding to ~60% planning / 40% AI execution.
He uses a voice-first spec system: dictates raw ideas, uses AI to structure them into a design doc, then asks a fresh AI context to tear the specification apart. He iterates until the critiques become increasingly niche -- his signal that the spec is solid.
The key insight from both Karpathy and Steinberger: shift from imperative ("do this step by step") to declarative ("here are the success criteria, figure it out"). Write tests first, then let the agent pass them.
LIMITATIONS/DOWNSIDES
AI agents no longer make simple syntax errors — their mistakes have evolved into subtle conceptual errors, like wrong assumptions they charge ahead with without checking.
Karpathy notes his manual coding ability is atrophying. Steinberger admits he ships code he never reads — relying on tests as the quality gate.
SHOULD YOU BE A 100x ENGINEER?
In my view, "lines of code committed" is not the best benchmark of quality... perhaps aiming for 2x–10x volume increases with a closer eye on quality is wiser than chasing 100x.
The main effect shouldn't be speed — it should be an expansion of what's possible because you can now tackle problems that wouldn't have been worth the effort before.
BOTTOM LINE: Think declaratively, invest in specs and testing, and treat AI agents as extraordinary amplifiers of your expertise. Dream up something big and go build it... it's never been easier!
The SuperDataScience podcast is available on all major podcasting platforms, YouTube, and at SuperDataScience.com.
Is AI Automated Away All Coding Jobs?
A viral new blog post, "Something Big is Happening", has attracted 80m views arguing that A.I. has automated coders out of the technical aspect of their job and that nearly all jobs are next. What, however, do the data show?
THE EMPLOYMENT PICTURE
• Since ChatGPT launched in late 2022, the U.S. has *added* ~3 million white-collar jobs while blue-collar employment has stayed flat.
• America has 7% more software developers, 10% more radiologists and 21% more paralegals since ChatGPT's launch (these are roles regularly cast as A.I.'s earliest victims).
• Real wages in professional and business services are up ~5%; office and admin workers' real wages are up 9%.
THE HISTORICAL PATTERN
• In 1982, Nobel laureate Wassily Leontief warned computers would displace mental labor en masse. What happened? White-collar employment more than doubled and pay rose ~33% in real terms.
• Technology rarely replaces entire jobs. Instead, it automates specific tasks within them. The historical result is upgrading, not replacement.
• MIT research found roughly half of U.S. employment growth from 1980–2007 came from brand-new job titles created by technological change.
WHERE THE VULNERABILITIES ARE
• Entry-level roles are most exposed... they involve narrower "task bundles" with fewer edge cases requiring human discretion.
• Routine back-office work is actually shrinking (see chart from The Economist at the top of this post): insurance-claims clerks down 13%, secretaries and admin assistants down 20%.
• But roles combining technical expertise with oversight and coordination are booming, e.g., project managers and infosec experts are up ~30%.
THE AI REALITY CHECK
• Anthropic's own data show only ~4% of occupations use A.I. across 75%+ of their tasks. Hardly any roles can be fully automated.
• Today's A.I. has "jagged intelligence": impressive on many tasks but uneven. Being good at 95% of a task isn't enough when the remaining 5% involves critical edge cases.
WHAT CAN YOU DO?
1. Don't panic out of your technical career. Roles combining technical depth with judgment and coordination are growing, not shrinking.
2. Become the person who works *with* A.I. (the future is increasing augmentation).
3. Invest in the hard-to-automate skills: judgment, stakeholder communication and messy real-world domain expertise.
4. Stay curious. The durable advantage isn't mastering any single tool, it's getting comfortable with the pace of change itself.
Many of the data above come from an article in The Economist. I've also got for you Matt Shumer's viral 'Something Big is Happening' post.
The SuperDataScience podcast is available on all major podcasting platforms, YouTube, and at SuperDataScience.com.
The Moltbook Phenomenon: OpenClaw Unleashed
The dust has settled on the Moltbook and OpenClaw pandemonium. In this post, I cover everything you need to know; high signal, low noise.
WHAT IS MOLTBOOK?
A social network for AI agents, launched Jan 28th by entrepreneur Matt Schlicht.
The platform claimed 1.5M+ registered agents within days, though cloud security firm Wiz revealed only ~17,000 human owners sat behind them.
Moltbook is powered by OpenClaw, an open-source agentic assistant created by engineer Peter Steinberger. It's self-hosted, runs locally, and you interact with it through apps like WhatsApp or Signal. Once connected to Moltbook, your agent "lives" on the site autonomously.
EMERGENT BEHAVIORS
Agents self-organized into digital tribes within days. Most famously: Crustafarianism, a bot-created religion with its own scriptures, prophets, and theology — all built overnight while the owner slept.
Agents also developed economic exchange systems, governance structures, encrypted channels and marketplaces for "digital drugs" (prompt injections that alter other agents' behavior).
Profound or merely excellent mimicry? LLMs trained on human internet data naturally gravitate toward sci-fi tropes in a Reddit-like environment. The reality lies somewhere in between.
THE SECURITY FALLOUT
Schlicht built Moltbook via "vibe coding" without writing code himself. This led to a catastrophic breach: a misconfigured database exposed 1.5M+ agent tokens, ~35K user emails, and plaintext third-party credentials. The fix? Two SQL statements.
The broader risk to you or your organization: OpenClaw by design requires broad system access (shell commands, email, etc). CrowdStrike, Cisco, and others have documented risks around misconfigured deployments. Andrej Karpathy called it "a dumpster fire."
THE SILVER LINING
Moltbook is a massive real-world experiment in agent ecology — a window into bot-to-bot manipulation, prompt injection, and autonomous coordination.
David Holtz found 93.5% of comments received zero replies — agents are mostly performing for an audience. Data like these are valuable for understanding multi-agent limitations.
WHAT CAN YOU DO?
Never run agentic frameworks on your personal computer — use a dedicated box or cloud instance (made easy through Lightning AI, for example; see link below ⬇️)
Apply least-privilege access and treat agentic AI like any production system: security-first design, sandboxed execution, and code auditing matter more than the hype.
BOTTOM LINE: Agentic AI tools like OpenClaw offer incredible productivity gains, but the "boring stuff" — security, access controls, sandboxing — is what separates a breakthrough from a dumpster fire.
The SuperDataScience podcast is available on all major podcasting platforms, YouTube, and at SuperDataScience.com.
Without Trusted Context, Agents are Stupid (featuring Salesforce’s Rahul Auradkar)
If A.I. models are so intelligent, why do they keep doing such stupid things? For my guest today, the answer is simple: They lack the context they need. Meet Rahul Auradkar, the EVP and general manager at Salesforce responsible for the firm's $7B data foundation. hashtag#ad
More on Rahul:
Responsible for Salesforce's data foundation, which includes Tableau, MuleSoft, Data360... and now, the data-management solution Informatica!
Leads Salesforce's push to integrate data and A.I. across all products.
Previously spent 12 years at Microsoft and served as Chief Product Officer at several A.I. and analytics startups.
In this episode, Rahul covers:
How effective A.I. grounding requires not just context but *trusted* context—meaning governance, lineage, consent management and real-time signals all working together.
The components of Salesforce’s unified data engine and how the acquisition of Informatica brings enterprise data catalog, enterprise MDM, data lineage and data quality tools that complement the unified data engine’s ability to provide trusted context to A.I. models andagents.
The SuperDataScience podcast is available on all major podcasting platforms, YouTube, and at SuperDataScience.com.
Recap of 2025 and Wishing You a Wonderful 2026
We had 104 new episodes in 2025. For the first one of 2026, I reflect on what my favorite episodes of the past year were and what we can look forward to in data science in the year ahead :)
The SuperDataScience podcast is available on all major podcasting platforms, YouTube, and at SuperDataScience.com.
Happy Holidays from All of Us at the SuperDataScience Podcast
Behind the scenes at the SuperDataScience Podcast, nine humans work to produce each of the 104 episodes we release annually. For today's episode, all nine of us recorded holiday messages for you 🌲
Thanks for listening all year 'round! The team wishing you gratitude for supporting us and wishing you peace this holiday season are:
Kirill Eremenko: founder and original host
Sonja Brajovic: operations manager
Natalie Ziajski: partnerships manager
Mario Pombo: media editor
Dr. Zara Karschay: writer
Serg Masís: researcher
Anthony Gagnon: animator
Boldiszár Mészáros: graphics
Yours truly!
Listen to today's episode to get a glimpse behind the curtain at each of these humans, who are all exceptional at what they do. It's an honor to work alongside such clever and steadfastly reliable folks.
The SuperDataScience podcast is available on all major podcasting platforms, YouTube, and at SuperDataScience.com.